H
e
l
l
o
W
o
r
l
d
(
)
;
I
'
m
G
o
p
i
M
a
g
u
l
u
r
i
M
L
E
n
g
i
n
e
e
r
|
D
a
t
a
S
c
i
e
n
t
i
s
t
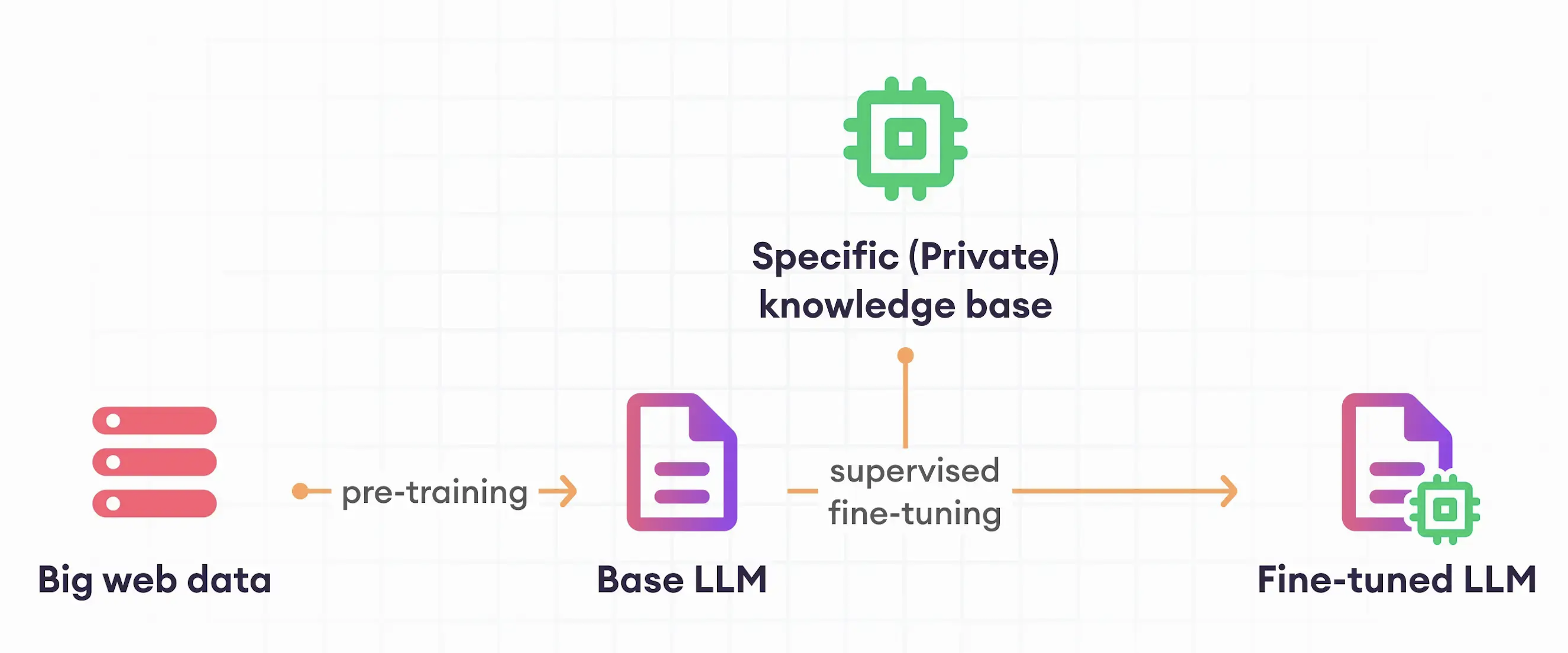
I'm a Machine Learning Engineer and Data Scientist with proven expertise in developing and deploying end-to-end AI solutions for complex business challenges. Specialized in NLP, LLM fine-tuning, and reinforcement learning techniques, with a track record of creating production-ready systems that deliver measurable impact. My experience includes building natural language interfaces for databases, implementing text ranking solutions, and developing intelligent document processing systems that drive operational efficiency and enhance decision-making capabilities across organizations.